# Anomaly Detection example
An autoencoder is a type of neural network that learns to reconstruct its input, making it useful for anomaly detection in signals. If a given input contains an unusual pattern that the network hasn't learned well, the reconstruction error will be high for that part, identifying the anomaly.
In this example, we will train an autoencoder to model a known periodic signal, which can flag anomalies via a large reconstruction error. We will use a Moku device to capture the signal data, then train a neural network model that can later be deployed on the Moku for real-time anomaly detection.
# Prepare the environment
Optional: if running on a fresh environment like Google Colab, install or upgrade the Moku API library (with Neural Network support) before proceeding.
# Uncomment and run this if Moku library is not installed
# !pip install -U "moku[neuralnetwork]"
2
First, we import the necessary Python libraries.
import csv
import os
import time
import numpy as np
import matplotlib.pyplot as plt
from tqdm.notebook import tqdm
2
3
4
5
6
7
Next, we import the Moku instrument classes we need, as well as the neural network model utilities.
from moku.instruments import MultiInstrument, Oscilloscope
try:
from moku.nn import LinnModel, save_linn
except ImportError:
print("Moku library is not installed. If running in an online notebook, install it with the pip command above.")
raise
2
3
4
5
6
7
We'll define some helper functions for later use, particularly for formatting and data I/O.
def format_sampling_rate(rate):
"""Format a sampling rate in Hz to kHz or MHz if applicable."""
if rate >= 1e6:
return f"{rate/1e6:.2f} MHz"
elif rate >= 1e3:
return f"{rate/1e3:.2f} kHz"
else:
return f"{rate:.2f} Hz"
def save_data_to_csv(data_points, window_size, filename):
"""Save 1D data points into CSV file, splitting into fixed-size windows per row."""
# Ensure all values are floats
data_points = [float(x) for x in data_points]
# Split data into consecutive windows of length window_size
windows = []
num_points = len(data_points)
i = 0
while i + window_size <= num_points:
windows.append(data_points[i:i + window_size])
i += window_size
# Handle the last partial window (pad or adjust start to full length)
if i < num_points:
start = max(0, num_points - window_size)
windows.append(data_points[start:num_points])
# Determine next ID for data frames by counting existing rows in file
file_exists = os.path.exists(filename)
next_id = 0
if file_exists:
with open(filename, 'r', newline='') as file:
reader = csv.reader(file)
next(reader, None) # skip header
next_id = sum(1 for _ in reader)
# Append new data windows to the CSV
with open(filename, 'a', newline='') as file:
writer = csv.writer(file)
if not file_exists:
writer.writerow(['id', 'data']) # write header if new file
for w in windows:
writer.writerow([next_id, ';'.join(f"{x:.6f}" for x in w)])
next_id += 1
def load_data_from_csv(filename):
"""Load data windows from the CSV file back into a list of lists of float values."""
data_windows = []
with open(filename, 'r', newline='') as file:
reader = csv.reader(file)
header = next(reader, None) # skip header if present
for row in reader:
if len(row) < 2:
continue # skip malformed rows
# Each row's second column is a ';'-separated list of values
values = [float(x) for x in row[1].split(';')]
data_windows.append(values)
return data_windows
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
We can see the available Moku devices, using the MokuCLI through the command line as a quick check.
! mokucli list
| Name | Serial | HW | FW | IP |
|------|--------|----|----|----|
| | | | | |
2
3
The above command should output a list of connected Moku devices with their name, serial, IP, etc. Ensure your Moku device is listed and reachable.
# Set up the Oscilloscope for data collection
First, set up the folder structure for organizaing output data and define the filename for captured data frames
# Define output folder and base filename
output_folder = "AD_dataset/"
output_filename = "data_training"
# Generate a unique filename with timestamp to avoid overwriting
timestamp = str(time.time()).split(".")[-1]
output_filename = f"{output_folder}{output_filename}_{timestamp}.csv"
print(f"Data will be saved in the file: {output_filename}" )
# Create the folder if it doesn't exist
if not os.path.exists(output_folder):
os.makedirs(output_folder)
print(f"Folder created: {output_folder}")
else:
print(f"Folder already exists: {output_folder}")
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
Data will be saved in the file: AD_dataset/data_training_7372458.csv
Folder already exists: AD_dataset/
2
Now, deploy the Oscilloscope instrument on your Moku. Connect to your Moku hardware by initializing a MultiInstrument with the device's IP address. In this example we use a Moku:Pro which has four slots available in its Multi-instrument Mode, so we set platform_id to 4.
Connections in Multi-Instrument Mode are defined by an array of dictionaries. In this example, we route the signal from the analog frontend (Input 1) to the first input channel of the Oscilloscope. We also define the coupling, attenuation, and impedance of the frontend.
Note: Replace '192.168.XX.XXX' with your Moku’s IP address (and adjust platform_id if using different Moku hardware).
# Connect to the Moku device and deploy an Oscilloscope instrument
mim = MultiInstrument('192.168.XX.XXX', force_connect=True, platform_id=4)
osc = mim.set_instrument(4, Oscilloscope)
connections = [dict(source="Input1", destination="Slot4InA")]
mim.set_connections(connections=connections)
mim.set_frontend(channel=1, impedance="50Ohm", coupling="DC", attenuation="-20dB")
2
3
4
5
6
7
{'attenuation': '-20dB', 'coupling': 'DC', 'impedance': '50Ohm'}
Configure the Oscilloscope acquisition parameters, including number of samples and how many frames of data to capture
# Acquisition parameters
window_size = 100 # number of samples per frame (window length)
n_frames = 100 # number of frames to capture for dataset
t1 = 0.0 # start time (seconds)
t2 = 0.1 # end time (seconds) for each frame
duration = t2 - t1
# Set the oscilloscope timebase for each frame capture
osc.set_timebase(t1, t2)
2
3
4
5
6
7
8
9
{'t1': 0.0, 't2': 0.1}
Now collect the data frames from the Oscilloscope via the get_data command. We will capture n_frames frames of channel data and save them to the CSV file defined above. The code below reads data from the Oscilloscope, uses our save_data_to_csv function to append each frame to the file, and prints progress as it goes.
for i in tqdm(range(n_frames), desc="Saving data"):
data = osc.get_data()
save_data_to_csv(data["ch1"], window_size, filename=output_filename)
2
3
Saving data: 0%| | 0/100 [00:00<?, ?it/s]
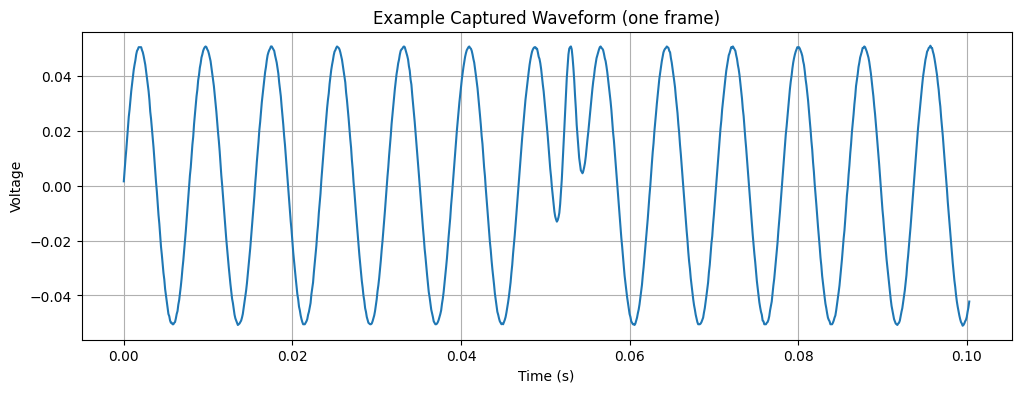
Now let's verify the sampling rate and examine one captured frame of data as an example
# Compute and display the sampling rate based on captured data
sampling_rate = osc.get_samplerate()
print("Sampling rate:", format_sampling_rate(osc.get_samplerate()["sample_rate"]))
# Plot an example frame of the captured data
plt.figure(figsize=(12, 4))
plt.plot(data["time"], data["ch1"])
plt.title("Example Captured Waveform (one frame)")
plt.xlabel("Time (s)")
plt.ylabel("Voltage")
plt.grid(True)
plt.show()
2
3
4
5
6
7
8
9
10
11
12
Sampling rate: 142.79 kHz
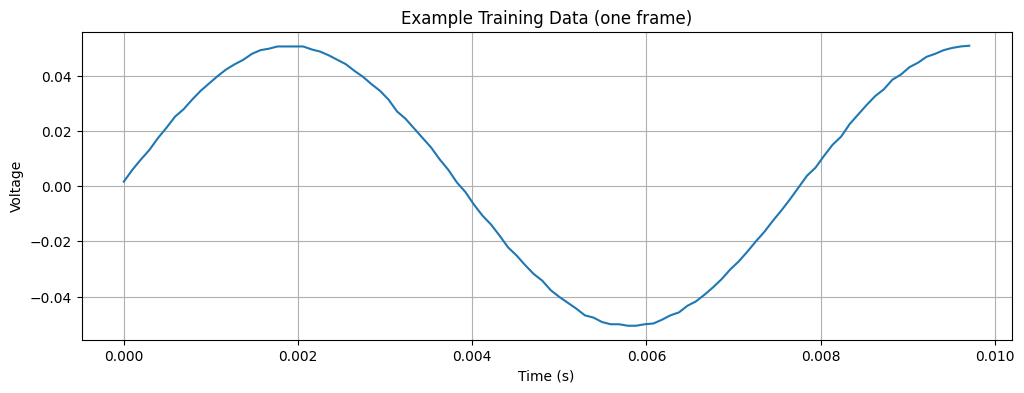
Print the first 100 datapoints of the frame. This 100-datapolint signal is an example of the training data that will be used for training the autoencoder.
# Plot an example frame of the training data
plt.figure(figsize=(12, 4))
plt.plot(data["time"][:100], data["ch1"][:100])
plt.title("Example Training Data (one frame)")
plt.xlabel("Time (s)")
plt.ylabel("Voltage")
plt.grid(True)
plt.show()
2
3
4
5
6
7
8
# Compose the training dataset
Now that data has been collected, we load it from the CSV and split it into separate training and testing sets. We will use a simple 80/20 split.
# Read the saved frames from CSV
data = load_data_from_csv(output_filename)
# Split into training and testing datasets (80% train, 20% test)
split_index = int(len(data) * 0.8)
full_training_dataset = data[:split_index]
full_testing_dataset = data[split_index:]
print(f"N. of frames in the training dataset: {len(full_training_dataset)}")
print(f"N. of frames in the testing dataset: {len(full_testing_dataset)}")
2
3
4
5
6
7
8
9
10
N. of frames in the training dataset: 880
N. of frames in the testing dataset: 220
2
# Define the model and train
Instantiate the Moku Neural Network model object using LinnModel.
quant_mod = LinnModel()
Set up an early stopping point for training to avoid overfitting. This will truncate the training if the validation loss does not improve for 10 epochs.
early_stopping_config = {
'patience': 10, # allow 10 epochs without improvement
'restore_best_weights': True,
'monitor':"val_loss"
}
2
3
4
5
6
Now, prepare the model definition. This is an autoencoder, a small fully-connected neural network that compresses and then reconstructs the input signal. The model will output the same number of samples as the input frame (100). We disable automatic scaling of data (scale=False) because we want to work with raw values.
frame_length = len(full_training_dataset[0])
print(f"frame length/input dimension: {frame_length}")
# Configure the model inputs/outputs (autoencoder: outputs = inputs)
quant_mod.set_training_data(training_inputs=full_training_dataset,
training_outputs=full_training_dataset,
scale=False)
# Define a simple autoencoder architecture:
# - encoder layers with 64, 32, 16 neurons (tanh activations)
# - final decoder layer with 'frame_length' neurons (linear activation)
model_definition = [
(64, 'tanh'),
(32, 'tanh'),
(16, 'tanh'),
(frame_length, 'linear')
]
# Build the model
quant_mod.construct_model(model_definition)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
Now train the model on the training dataset we defined earlier. We include a 10% validation split (which comes from the training set itself) for early stopping.
history = quant_mod.fit_model(
epochs=250,
es_config=early_stopping_config,
validation_split=0.1,
verbose=1
)
2
3
4
5
6
Value for restore missing. Using default:False.
Epoch 1/250
25/25 ━━━━━━━━━━━━━━━━━━━━ 1s 6ms/step - loss: 0.0013 - val_loss: 7.8818e-04
Epoch 2/250
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 6.5409e-04 - val_loss: 2.8883e-04
Epoch 3/250
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 2.1046e-04 - val_loss: 6.5728e-05
[...]
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 3.8480e-07 - val_loss: 5.1594e-07
Epoch 62/250
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 3.4140e-07 - val_loss: 4.6303e-07
Epoch 63/250
25/25 ━━━━━━━━━━━━━━━━━━━━ 0s 3ms/step - loss: 5.4634e-07 - val_loss: 6.4741e-07
2
3
4
5
6
7
8
9
10
11
12
13
14
15
Plot the training and validation loss history to confirm convergence.
plt.semilogy(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.legend(['train loss', 'val loss'])
plt.xlabel('Epochs')
plt.ylabel('MSE Loss')
plt.show()
2
3
4
5
6
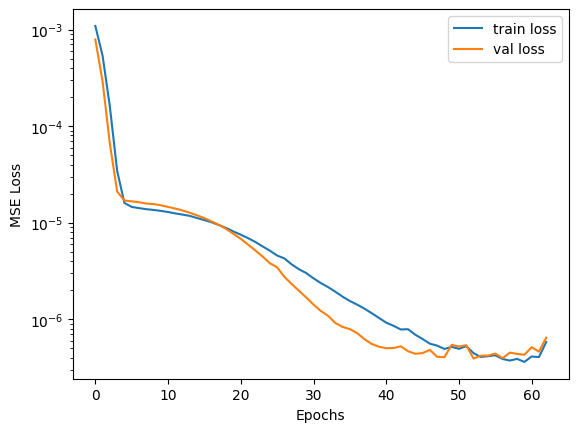
In this case, the final loss values are extremely low, indicating the autoencoder learned to reconstruct our sine wave signals very accurately. Next, save the quantized model to a file using save_linn. This will produce a .linn file that can be deployed to the Moku device’s FPGA for real-time inference.
model_filename = "AD_model.linn"
# Create a time-base array for mapping (same length as frame)
T = np.linspace(-1, 1, frame_length)
# Save the trained model to file
save_linn(quant_mod, input_channels=1, output_channels=1,
file_name=model_filename, output_mapping=[T.size-1])
2
3
4
5
6
Skipping layer 0 with type <class 'keras.src.layers.core.input_layer.InputLayer'>
Skipping layer 2 with type <class 'moku.nn._linn.OutputClipLayer'>
Skipping layer 4 with type <class 'moku.nn._linn.OutputClipLayer'>
Skipping layer 6 with type <class 'moku.nn._linn.OutputClipLayer'>
Skipping layer 8 with type <class 'moku.nn._linn.OutputClipLayer'>
Network latency approx. 224 cycles
2
3
4
5
6
# Testing the model - reconstruct the training dataset
Now that the model is trained, let’s verify how well it performs on data it saw during training. We feed the entire training dataset through the model to get reconstructed signals.
full_training_dataset_np = np.array(full_training_dataset)
reconstructions = quant_mod.predict(full_training_dataset_np, scale=False, unscale_output=False)
2
28/28 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step
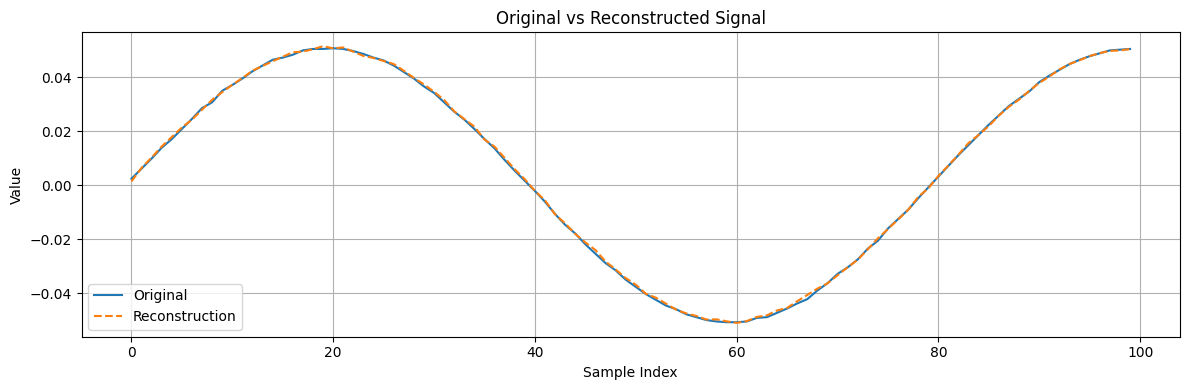
The reconstructions array contains the model output for each input frame. For a well-trained autoencoder, these reconstructed frames should closely match the originals. As a quick visual check, we can pick one training frame and compare it with its reconstruction
frame_id = 0 # for example, take the first training frame
plt.figure(figsize=(12, 4))
plt.plot(full_training_dataset[frame_id], label='Original')
plt.plot(reconstructions[frame_id], label='Reconstruction', linestyle='--')
plt.legend()
plt.title('Original vs Reconstructed Signal')
plt.xlabel('Sample Index')
plt.ylabel('Value')
plt.grid(True)
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
11
# Testing the model on the unseen dataset
Now we evaluate the autoencoder on the frames the model has not seen before. We expect the model to reconstruct normal frames well, but frames with anomalies (such as glitches) should yield a larger reconstruction error since the model was not trained on that behavior.
First, generate reconstructions for all test frames.
full_testing_dataset_np = np.array(full_testing_dataset)
reconstructions_test = quant_mod.predict(full_testing_dataset_np)
2
7/7 ━━━━━━━━━━━━━━━━━━━━ 0s 2ms/step
To illustrate the model’s performance, let's compare the output on a specific test frame that contains a known anomaly versus a test frame that is normal. Suppose we know that frame index 147 in our dataset contains a glitch, and frame 146 is a normal frame for comparison.
frame_id_anomaly_test = 31
frame_id_normal_test = 146
# Plot original vs reconstructed for the anomalous frame
plt.figure(figsize=(12, 4))
plt.plot(full_testing_dataset[frame_id_anomaly_test], label='Original')
plt.plot(reconstructions_test[frame_id_anomaly_test], label='Reconstruction', linestyle='--')
plt.legend()
plt.title('Original vs Reconstructed Signal (Anomalous frame)')
plt.xlabel('Sample Index')
plt.ylabel('Value')
plt.grid(True)
plt.tight_layout()
plt.show()
# Plot original vs reconstructed for a normal frame
plt.figure(figsize=(12, 4))
plt.plot(full_testing_dataset[frame_id_normal_test], label='Original')
plt.plot(reconstructions_test[frame_id_normal_test], label='Reconstruction', linestyle='--')
plt.legend()
plt.title('Original vs Reconstructed Signal (Normal frame)')
plt.xlabel('Sample Index')
plt.ylabel('Value')
plt.grid(True)
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
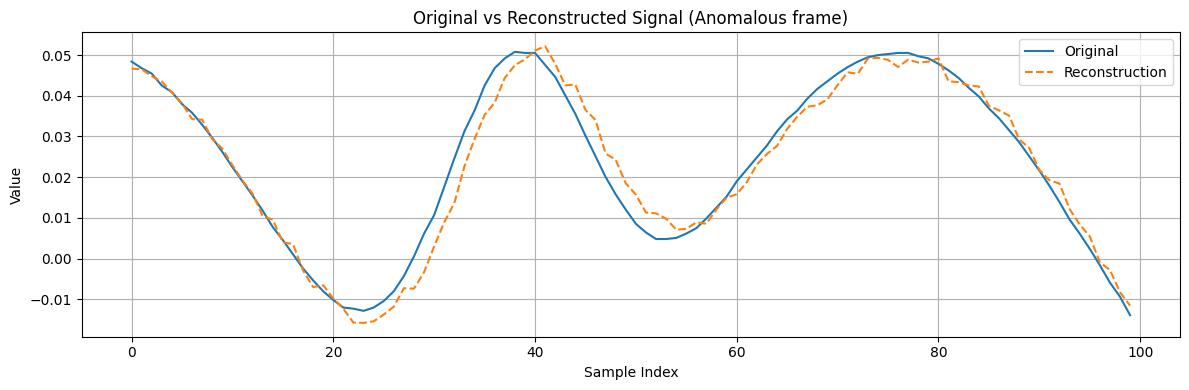
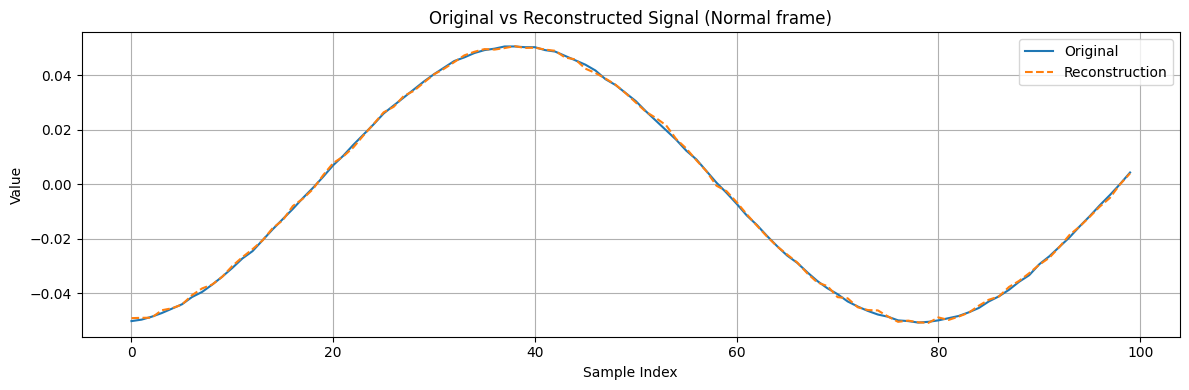
To detect the anomaly quantitatively, we need to examine the reconstruction error.
# Extract the reconstruction error
Calculate the element-wise error between original and reconstructed signals for the test set.
original = np.array(full_testing_dataset)
reconstructed = np.array(reconstructions_test)
# --- Error calculations ---
# Absolute error for each sample
absolute_error = np.abs(original - reconstructed)
# Squared error for each sample
squared_error = (original - reconstructed) ** 2
# Summed error per frame (could be used as an anomaly score per frame)
absolute_error_per_frame = absolute_error.sum(axis=1)
squared_error_per_frame = squared_error.sum(axis=1)
2
3
4
5
6
7
8
9
10
11
12
Now, compare the error profiles of the previously chosen anomalous frame with the normal frame. We expect the frame with the glitch to show a spike in error at the glitch location, whereas the normal frame’s error should remain near zero across all sample indices. For example, we can plot the squared error for both frames on the same graph.
plt.figure(figsize=(12, 4))
plt.plot(squared_error[frame_id_anomaly_test], label='Frame with anomaly', color='orange')
plt.plot(squared_error[frame_id_normal_test], label='Normal Frame', color='blue')
plt.title('Reconstruction Squared Error (per sample)')
plt.xlabel('Index')
plt.ylabel('Error')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
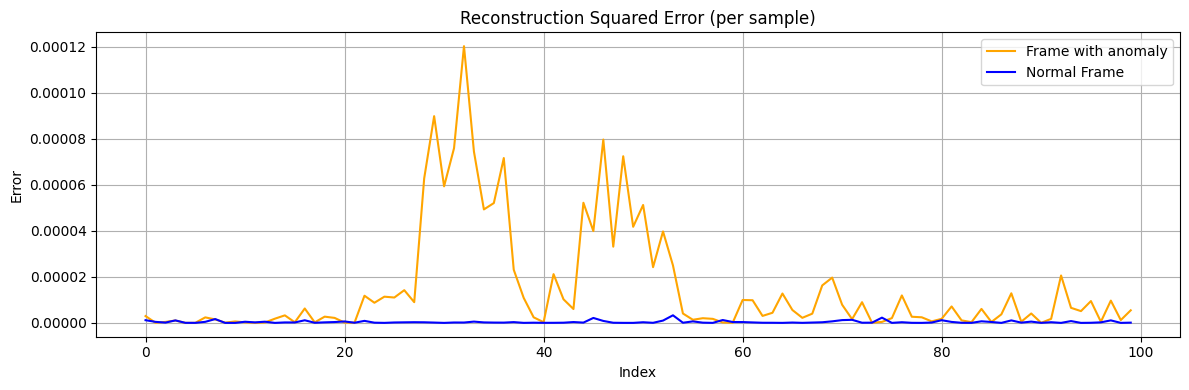
In the plot above, the anomalous frame (orange curve) has several spikes in error, whereas the normal frame error (blue line) is essentially flat at zero. This indicates the autoencoder was unable to reconstruct those glitch points, as expected.
We can further quantify this by applying a numerical threshold. In this example we'll set this threshold at an absolute error of 0.0002.
threshold = 0.0002
# Find indices in the anomaly frame where absolute error > threshold
indices_anom = [i for i, v in enumerate(squared_error[frame_id_anomaly_test]) if v > threshold]
values_anom = [squared_error[frame_id_anomaly_test][i] for i in indices_anom]
print("Frame with anomaly")
print("Indices of values > threshold:", indices_anom)
print("Corresponding values:", values_anom)
print("—" * 70)
# Find indices in the normal frame where absolute error > threshold
indices_norm = [i for i, v in enumerate(squared_error[frame_id_normal_test]) if v > threshold]
values_norm = [squared_error[frame_id_normal_test][i] for i in indices_norm]
print("Normal frame")
print("Indices of values > threshold:", indices_norm)
print("Corresponding values:", values_norm)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Frame with anomaly
Indices of values > threshold: []
Corresponding values: []
——————————————————————————————————————————————————————————————————————
Normal frame
Indices of values > threshold: []
Corresponding values: []
2
3
4
5
6
7
As expected, the anomalous frame has a few samples where the reconstruction error exceeds the threshold, while the normal frame has none. These correspond to the glitch points in the signal.
To further reduce false detections, we experimented with using higher-order error metrics. For example, defining a "focal MSE loss" (squared error raised to a power >1) can down-weight small differences and emphasize larger errors.
def focal_mse_loss(prediction, target, gamma=2.5):
error = prediction - target
squared_error = error ** 2
return squared_error ** gamma
# Compute focal loss for each sample
focal_loss = focal_mse_loss(reconstructed, original)
focal_loss_per_frame = focal_loss.sum(axis=1)
2
3
4
5
6
7
8
plt.figure(figsize=(12, 4))
plt.plot(focal_loss[frame_id_anomaly_test], label='Frame with anomaly', color='orange')
plt.plot(focal_loss[frame_id_normal_test], label='Normal Frame', color='blue')
plt.title('Reconstruction Focal Loss (per sample)')
plt.xlabel('Index')
plt.ylabel('Error')
plt.legend()
plt.grid(True)
plt.tight_layout()
plt.show()
2
3
4
5
6
7
8
9
10
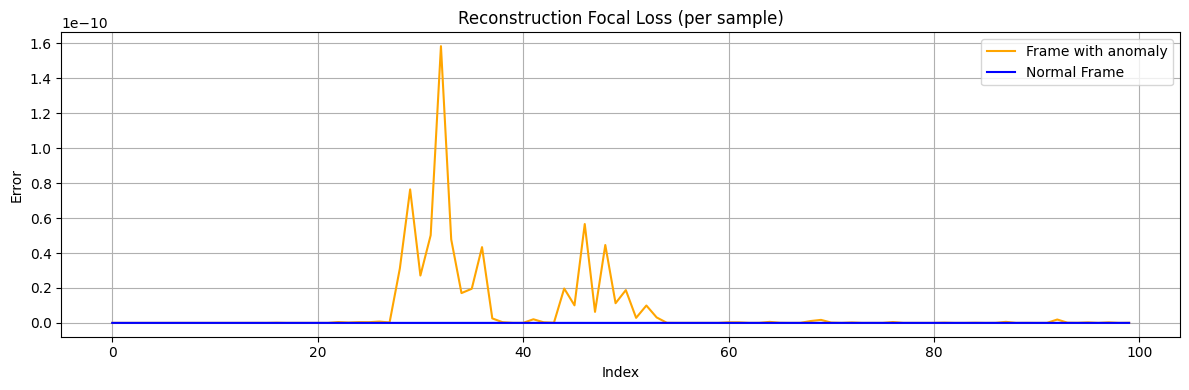
threshold = 1e-9
# Find indices where value > threshold
# Frame with Anomaly
indices = [i for i, v in enumerate(focal_loss[frame_id_anomaly_test]) if v > threshold]
# Print results
print("Frame with anomaly")
print("Indices of values > threshold:", indices)
print("Corresponding values:", [focal_loss[frame_id_anomaly_test][i] for i in indices])
print("-------------------------------------------------------------------------------")
# Normal with Anomaly
indices = [i for i, v in enumerate(focal_loss[frame_id_normal_test]) if v > threshold]
# Print results
print("Normal frame")
print("Indices of values > threshold:", indices)
print("Corresponding values:", [focal_loss[frame_id_normal_test][i] for i in indices])
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
Frame with anomaly
Indices of values > threshold: []
Corresponding values: []
-------------------------------------------------------------------------------
Normal frame
Indices of values > threshold: []
Corresponding values: []
2
3
4
5
6
7
Overall, the autoencoder approach successfully learned the normal signal behavior and flagged the anomaly via reconstruction error. In summary:
- Normal frames: Reconstructed almost perfectly, with near-zero error across all samples.
- Anomalous frame: Reconstruction deviates at the glitch points, yielding measurable error spikes.
This demonstrates how an FPGA-deployable autoencoder, trained via Moku’s Python API, can perform real-time anomaly detection on signal data. The .linn model file saved can be loaded onto the Moku device to monitor incoming signals and detect anomalies based on the model’s reconstruction error in real time.
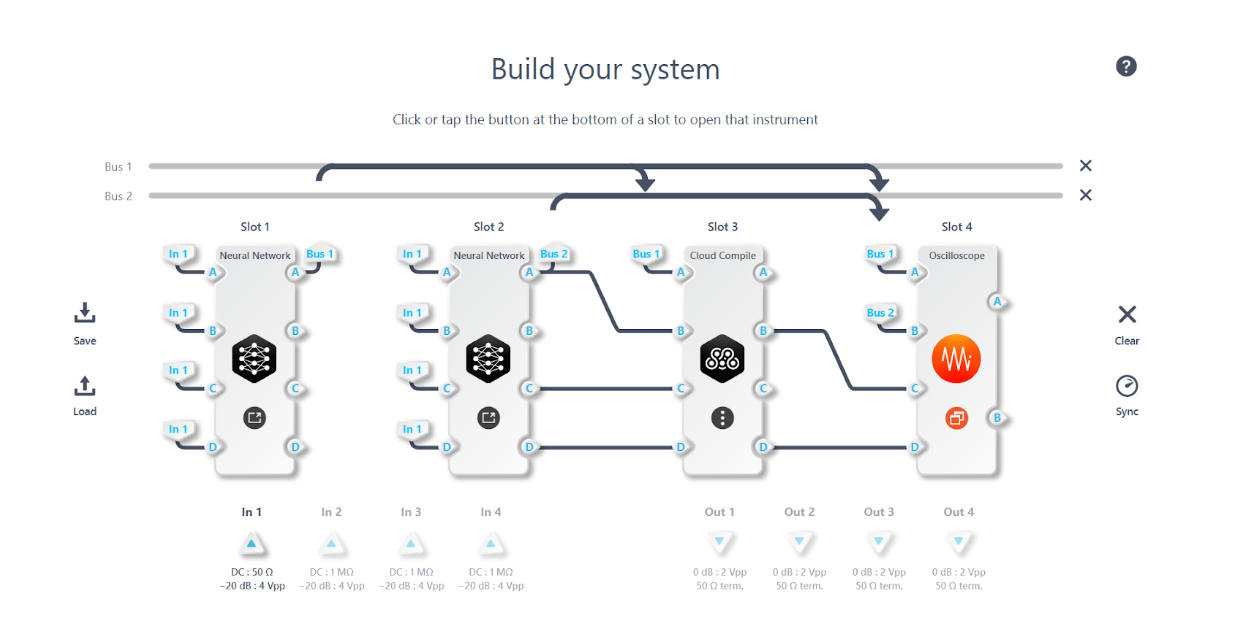
# Deploy on Moku
To test the model and deploy the anomaly detection feature, open your Moku on Multi-Instrument Mode.
Place the Neural Network instrument into Slot 1 and load the .linn file. Route the signal source to the Neural Network input (e.g., the output of a Waveform Generator or an external signal source), and enable the output. The Neural Network will output the reconstructed signal in real time.
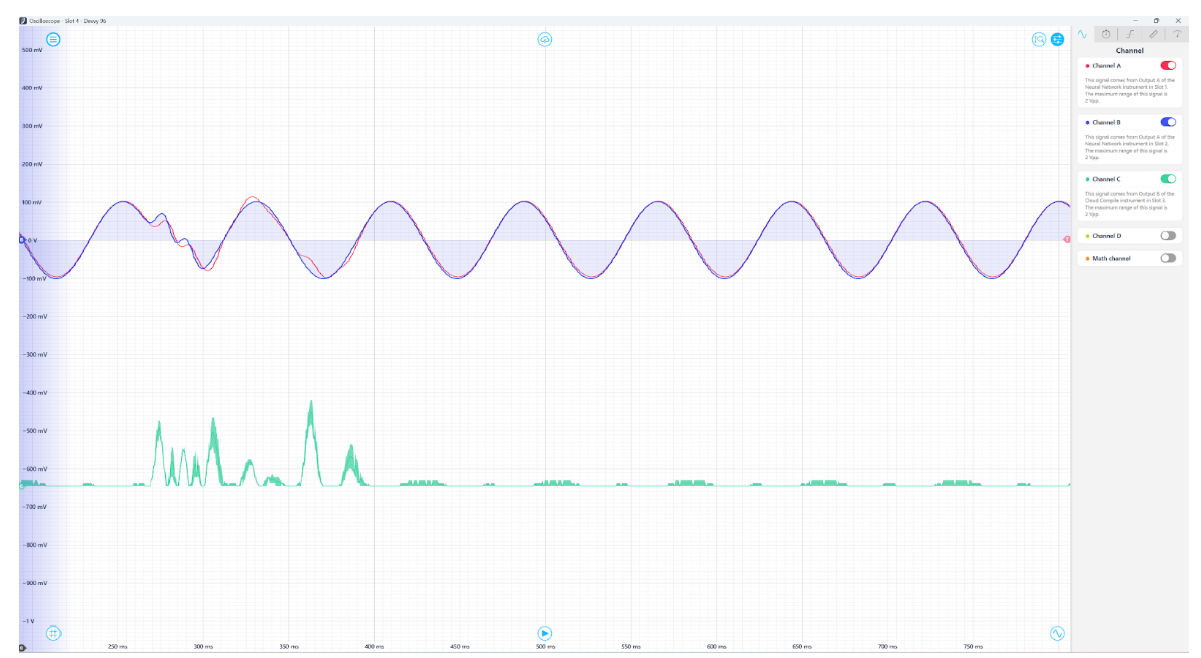
You can then place an Oscilloscope in another slot to visualize both the original and reconstructed signals simultaneously. You should see that the reconstructed signal closely tracks the original except when anomalies occur, as we observed in the offline test. The reconstructed signal might be slightly delayed relative to the original due to some finite latency. One strategy to compensate for this is to deploy a second Neural Network instrument configured as an identity network (a network that simply outputs its input) in another slot to delay the original signal by the same amount. By aligning the phase in this way, you can directly compare the original and autoencoder output signals.
To automate anomaly detection, you can measure the difference between the original and reconstructed signals on the Moku. For example, you could use a custom Moku Compile module that outputs the squared error. This error signal will spike when the original signal deviates from the learned normal pattern, which can be detected using a threshold trigger on the Oscilloscope or Data Logger.
← Overview Autoencoder →