# Outputting a weighted sum of inputs
In this tutorial, you will learn the fundamentals of using the provided neural network library for training a Moku Neural Network to deploy on Moku:Pro. This library uses the Tensorflow (opens new window) implementation of Keras (opens new window) to instill best practices for deploying an FPGA-based neural network. In this example, we will train a basic model to output a weighted sum of the input chnnels with an optional bias/offset term using a single layer with a single neuron.
import numpy as np
import matplotlib.pyplot as plt
from moku.nn import LinnModel, save_linn
2
3
4
# Step 1: Generate input (3 channels) and output (one channel) data for training
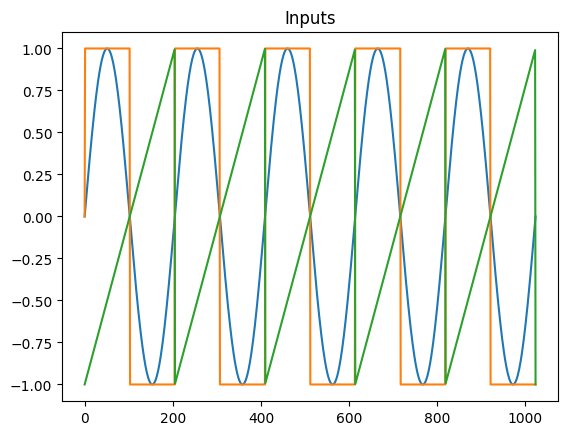
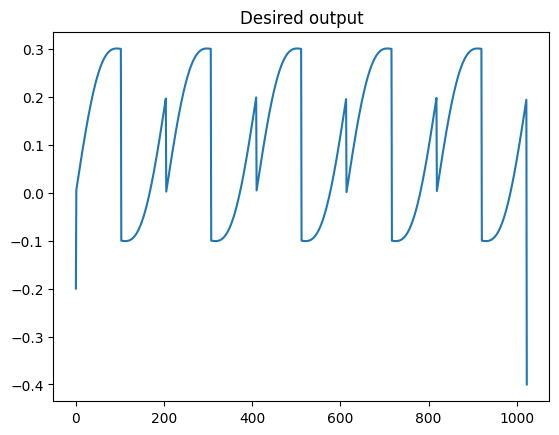
Generate training data and plot the simulated signals to verify them. You can also choose to use Moku to produce training data.
nPts = 1024
nCycles = 5
x = np.linspace(0, nCycles * 2 * np.pi, nPts)
in1 = np.sin(x)
in2 = np.sign(in1)
in3 = 1/np.pi * ((x % (2*np.pi)) - np.pi)
offset = 0.1
amp1 = 0.1
amp2 = 0.2
amp3 = 0.3
out = amp1*in1 + amp2*in2 + amp3*in3 + offset
plt.figure()
plt.plot(in1)
plt.plot(in2)
plt.plot(in3)
plt.title('Inputs')
plt.figure()
plt.plot(out)
plt.title('Desired output')
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
Text(0.5, 1.0, 'Desired output')
# Step 2: Defining the model and train the neural network
Now that we have defined the training data we need to define a model which we will then subsequently train. A neural network is made of succesive layers of connected neurons that implement a generally non-linear mapping of a linear transform: $A(Wx + b)$, where $W$ is the weight matrix, $x$ is an input vector, $b$ is a bias vector and $A$ is the activation function. By successively stacking and connecting arbitrarily large numbers of artificial neurons, a neural network becomes a unviersal approximator. While there are many different types of neural networks, the Moku FPGA currently only supports densely connected feedforward networks. More information on these type of networks, otherwise known as multilayer perceptrons, can be found here: Goodfellow-Ch6 (opens new window).
We also reshape the data to reflect that we have N number of training examples of size 1. In general, training data should allow for the mapping $(N, M)\mapsto(N, K)$ where N is the number of training examples, M is the input feature dimension and K is the output feature dimension. In this case we are looking to map $X \mapsto Y$ where both X and Y have shape (N, 1).
# Reshape the inputs, ready for training. Each `data point' is three inputs and one output
inputs = np.vstack((in1, in2, in3)).transpose() # Shape is now nPts x 3
out.shape = [nPts, 1] # Shape is now nPts x 1
2
3
4
We need to define the model structure that we will use to represent the functional mapping. To do this, we will define a simple model with only one dense layer of a single neuron and a linear activation function. We provide a model definition as a list of tuples, where each tuple can take the form: (layer_size, activation).
Build the neural network model. Skip the I/O scaling as the data is sufficient for training, Note that if you add scaling here, you'll need to apply the same scaling in the Moku Neural Network instrument at runtime.
linn_model = LinnModel()
linn_model.set_training_data(inputs, out, scale=False)
model_definition = [ (1, 'linear')] # A linear model should give a perfect prediction in this contrived case
# Try some of the others below
# model_definition = [ (4, 'relu'), (4, 'relu')] # ReLU activation not great on signal reconstruction
# model_definition = [ (4, 'tanh'), (4, 'tanh')] # tanh has a range of +-1 which is more "voltage-like"
# model_definition = [ (16, 'tanh'), (16, 'tanh')] # A few more degrees of freedom to play around with
# model_definition = [ (100, 'tanh'), (100, 'tanh'), (100, 'tanh'), (100, 'tanh'), (100, 'tanh')] # Biggest Moku can fit, can overfit!
linn_model.construct_model(model_definition)
2
3
4
5
6
7
8
9
10
11
12
**Model: "functional"**
| Layer (type) | Output Shape | Param # |
|-------------------------------------|------------------|---------|
| input_layer (InputLayer) | (None, 3) | 0 |
| dense (Dense) | (None, 1) | 4 |
| output_clip_layer (OutputClipLayer) | (None, 1) | 0 |
**Total params:** 4 (16.00 B)
**Trainable params:** 4 (16.00 B)
**Non-trainable params:** 0 (0.00 B)
2
3
4
5
6
7
8
9
10
11
Here we can see our dense layers that match the size that we defined. There are a number of intermediate layers listed as output_clip_layer which can be ignored. These layers are a byproduct of the quantisation for the Moku implmentation and are automatically added by the quantised model.
Now that we have defined our model, we need to train it so that it will represent our desired mapping. This is as simple as calling the fit_model() function with a few simple arguments. We will allow our model to train for 500 epochs (training steps) and will pass our validation data that we used earlier.
# %%
# Train the model. This simple model converges quickly, so an early stopping config terminates training much more quickly.
history = linn_model.fit_model(epochs=500, validation_split=0.1, es_config={'patience': 10})
2
3
4
Value for monitor missing. Using default:val_loss.
Value for restore missing. Using default:False.
Epoch 1/500
[1m29/29[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 5ms/step - loss: 0.6554 - val_loss: 0.4668
Epoch 2/500
[1m29/29[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 809us/step - loss: 0.5419 - val_loss: 0.4265
Epoch 3/500
[1m29/29[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 826us/step - loss: 0.4624 - val_loss: 0.3913
Epoch 4/500
[1m29/29[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 729us/step - loss: 0.4268 - val_loss: 0.3574
Epoch 5/500
[1m29/29[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 722us/step - loss: 0.3563 - val_loss: 0.3288
Epoch 6/500
[1m29/29[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 729us/step - loss: 0.3183 - val_loss: 0.3044
.
.
.
.
.
Epoch 347/500
[1m29/29[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 829us/step - loss: 2.7716e-15 - val_loss: 3.8252e-15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
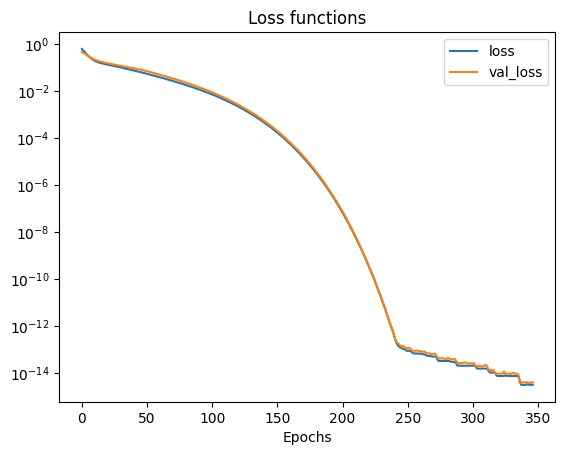
We can use the returned history object to view the training and validation loss as a function of the training epochs. As training continues we can see that again the validation loss reduces and we end up with a model that has generalized to the training data.
# plot the losses
plt.figure()
plt.semilogy(history.history['loss'])
plt.semilogy(history.history['val_loss'])
plt.legend(['loss', 'val_loss'])
plt.xlabel('Epochs')
plt.title('Loss functions')
plt.show()
2
3
4
5
6
7
8
Optionally, we can view the performance of our model on our data by plotting the models predictions. In general, training an accurate model will be a function of many variables including choice of activation function, number of layers, number of neurons and the structure of the training data.
# %%
# Plot the error between the actual and predicted points
nn_out = linn_model.predict(inputs)
fig, axs = plt.subplots(2)
fig.suptitle('Predicted output')
axs[0].plot(out,label='Desired')
axs[0].plot(nn_out,'--',label='Model output')
axs[0].legend()
axs[1].plot(nn_out-out,label='Model - Desired')
axs[1].legend()
plt.subplots_adjust(wspace=0.5, hspace=0.5)
plt.show()
2
3
4
5
6
7
8
9
10
11
12
13
[1m32/32[0m [32m━━━━━━━━━━━━━━━━━━━━[0m[37m[0m [1m0s[0m 330us/step
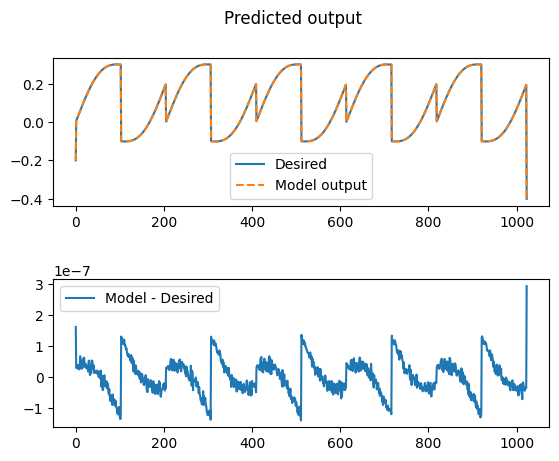
Note the scale on the plot mapping the difference between model output and desired output.
# Step 3: Save the model to disk for use in the Moku Neural Network instrument.
The neural network is completely described by its weights and biases. In this simple case, we can inspect these values and compare them to the function that was used to generate the data in the first place. Note that it has almost exactly learned the original function.
#Print model weights for interest and education
ii = 0
for layer in history.model.layers:
if layer.get_weights():
print(f'{ii}: ', 'Weights',layer.get_weights()[0].flatten().tolist(), ', Biases',layer.get_weights()[1].flatten().tolist())
ii = ii + 1
# Save the model to a .linn file
save_linn(linn_model.model, input_channels=3, output_channels=1, file_name='Sum.linn')
2
3
4
5
6
7
8
9
10
0: Weights [0.1000000610947609, 0.1999998688697815, 0.29999983310699463] , Biases [0.10000000149011612]
Skipping layer 0 with type <class 'keras.src.layers.core.input_layer.InputLayer'>
Skipping layer 2 with type <class 'moku.nn._linn.OutputClipLayer'>
Network latency approx. 6 cycles